Requested Information for Code
Readings
Some scientists, including economists, have put together excellent guidance and tutorials. See
- Reif’s Stata coding guide and a sample project setup that supports reproducibility
- Gentzkow-Shapiro Lab’s RA Manual, in particular Stata Style
- Basics of Reproducible Workflow
- Good enough practices in scientific computing. Wilson G, Bryan J, Cranston K, Kitzes J, Nederbragt L, et al. (2017) Good enough practices in scientific computing. PLOS Computational Biology 13(6): e1005510. https://doi.org/10.1371/journal.pcbi.1005510
README and master script
All replication archives should have a README (in PDF, text, or a simple formatting language such as Markdown, like this document). The README should provide a sufficient description to understand the structure of the replication archive (directory structure, what is acquired from third parties, what is generated by scripts, how much output to expect). It should document each file or class of files that are included.
We strongly encourage the provision of a master script. The master script should run all programs necessary to provide the outputs, in the right sequence, robustly.
In some cases, the master script might also serve as a README (for instance, “README.bash”, “README.py”, “README.Rmd”), as long as it satisfies all conditions of the README as well (i.e., ample comments).
Configuration
We strongly encourage the use of a single configuration file, containing all path names.
We strongly encourage the use of relative paths for including programs, data, and outputs in the main program
We strongly encourage listing ALL dependencies and packages needed to run.
- including them in the project
- or listing them out in a “setup” program
We strongly encourage setting any seeds for random number generators
Things not to do
- We strongly discourage writing comments like
Run this a first time, generating column 1 of Table 3.
Then comment out line 55, then run a second time, which should
give you column 3 of Table 3.
Then uncomment line 55, change the parameter in line 67 to "5",
and run again to get column 2 of Table 3.(this is only slightly paraphrased from an actual example). - Avoid ambiguous or imprecise instructions like
Have superDynare availableor
Use the outreg55 package(no URL or installation command provided)

Things to do
- Explain briefly how to RUN your code - do not assume that everybody now or in the future knows how to run
make, Matlab+Dynare, or even Stata. - Write code that can be run without human intervention, ideally without using a graphical interface.
- Use functions/programs/loops/etc. to iterate through variations of an otherwise identical procedure (but ensure that the purpose of the loop is well described)
- Identify all requirements to allow somebody to successfully run the code who has NOT been experimenting with the software and code for the past 5 years on the same laptop. This means
- what packages need to be installed, from where, which versions
ssc install outreg55, from(https://myurl/to/o) // accurate as of 2018-10-03or r # Known to work with dplyr 0.7.6 install.packages(c("dplyr","devtools")) library(dplyr) library(devtools) install_github("myrepo/superols") - Write out all tables to files (do not simply display on-screen) - Stata: regsave, outest, texsave, etc. are sample packages - Matlab: writetable - R: any number of packages, for instance kable or kableExtra - Write out all figures to files (do not simply display on-screen) - Stata: graph export (use pdf or eps) - Matlab: saveas - R: various native commands, such as png(), pdf()
Versioning of packages
You should be precise about the relevant packages. Ideally specify a specific version to install, or provide the package. At a minimum, specify the version of a package that you produced your results with.
- Stata:
- making a distinction between Stata Journal and SSC versions can sometimes help. If the package license permits, distributing the package with the core code is also possible.
- Redirect the
adopathto a project-specific directory.
- R:
- you could fix things by installing specific versions, see Installing older versions of packages.
- use of MRAN snapshot
- use of
packratpackages (much local storage)
Some facts
Most economists in the late 2000s (through 2018) use either Stata or Matlab. Assume that replicators have not (yet) learned your preferred software if you are using something else, and provide some guidance how to use it.
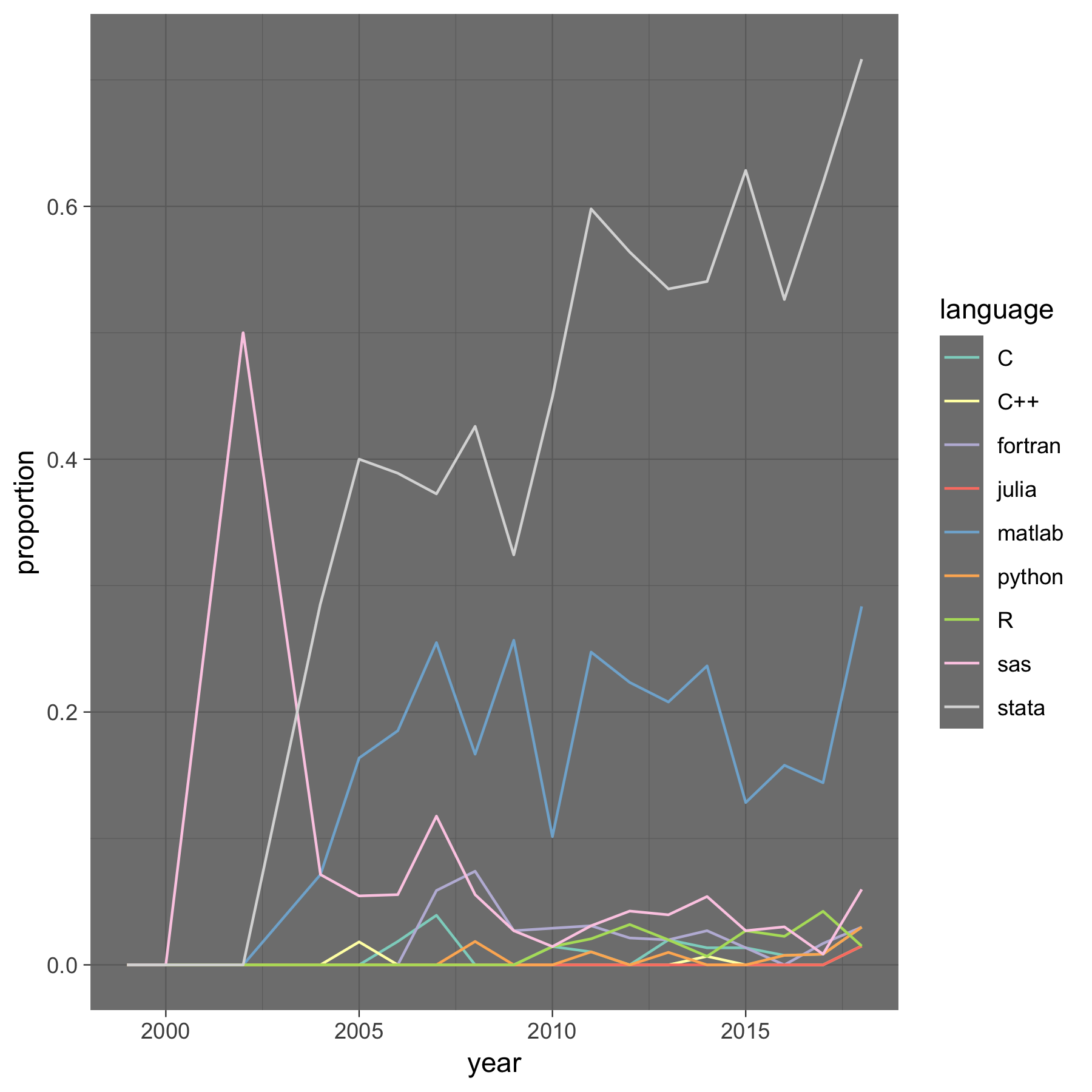 Figure: Software usage in the AER, 2000-2018 (Source: Baylis and Schrimpf, 2018)
Figure: Software usage in the AER, 2000-2018 (Source: Baylis and Schrimpf, 2018)